

ビット量子化について勉強してたら、ふと亡くなったおばあちゃんのことを思い出したよ、という話。
ビット量子化とは
LLMが内部の重みを「細かく覚える」のをやめて、だいたいの値だけで覚えるようにすることで、メモリを節約し、処理を速くする工夫のこと。
だそうです。ざっと言うと、
本当は「12.3456789」だった数字を、「12」だけにする。
本当は「0.9876543」だったのを、「1」にしてしまう。
みたいなことですね。
実際には単純に数字を減らすだけではなく、情報量を落とさずに「どの数字をまとめるか」を賢く決める技術が使われることで、メモリ消費量を落としつつも賢さはある程度維持できるようになっているそうです。(ここ大事)
例えば私の好きなモデル、Gemma 3の27bだと、量子化前は約54 GBありますが、ollamaで使用されるのはQ4_K_Mという4ビット量子化版で、約17GBに軽量化されているそうです。これによりMac-miniのメモリ64GBでも利用することが出来ます。
おばあちゃんとは
息子と孫が男ばっかりで、名前をどんどん覚えなくなっていったうちのおばあちゃんのこと。
ざっくりと覚えることでメモリ省エネ化する って話でふと、「ばあちゃんの頭の中こんな感じだったのかもな」 と思ったわけです。その話をChatGPTにしたら、

とやたらとウケてくれまして。ブログにしようかなと思ったわけです。
ビット量子化には段階がある
以下ChatGPTがおばあちゃんに例えてくれました。
🎚️ 8ビット量子化(ほどよく賢いおばあちゃん)
数字を 256段階(0~255) で表現する。
元の数値(たとえば32ビットの浮動小数点)をざっくりまとめる。
ほとんど精度は落ちない。
多くの現場で「高速化・省メモリ化」の標準。
👵 たとえ:
おばあちゃんは孫の名前の最初の文字くらいは覚えている。
「たろう」「たかし」は区別できるけど、「たけし」と「たける」はちょっと混ざる。
🧩 技術的には:
- ほぼ「知的なおばあちゃん」レベル
- 精度99%以上保てることも多い
- GPU・CPUともにサポート豊富
🎛️ 4ビット量子化(かなりざっくりなおばあちゃん)
数字を 16段階(0~15) でしか表せない。
メモリ消費は1/8になる(元が32ビットなら)。
でも、情報が少ない分、「少し判断ミス」が増える。
👵 たとえ:
おばあちゃんはもう名前は思い出せない。
「男の子か女の子か」「背の高い子か低い子か」ぐらいで判断して、
全員を「孫A」「孫B」くらいで呼んでる感じ。
🧩 技術的には:
- 精度は少し落ちるが、スピードと省メモリ効果が大きい
- 4bit LLM(例:Q4_K_M形式など)は、家庭用PCでも大きなモデルを動かせる
- GemmaやLLaMAの軽量版でよく使われる
🔘 2ビット量子化(もはや“孫”しか言わないおばあちゃん)
数字を 4段階(0~3) でしか表せない。
さらに軽くなるが、かなりの精度低下を起こす。
👵 たとえ:
おばあちゃんは全員「孫」で呼ぶ。
犬を見ても孫、郵便屋さんを見ても孫。
つまり「だいたいそうだけど細かい違いはわからない」状態。
🧩 技術的には:
- 精度が大きく落ちやすく、用途は限られる
- 研究段階や特殊用途(省メモリデバイスなど)で使われることが多い
- 推論(話すとき)だけなら意外と動くこともある
なるほどわかりやすい。
うちのおばあちゃんの例でいうとこんな感じかな。
元データはこんな感じ(名前は仮名)
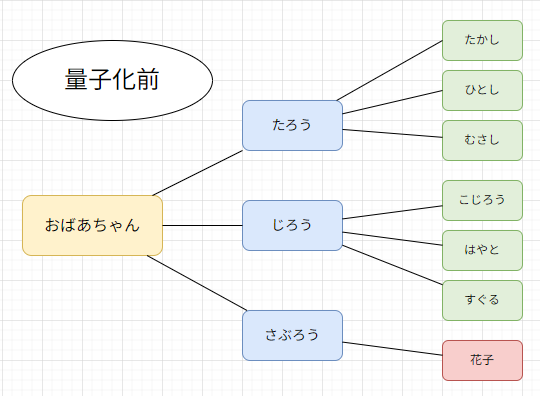
70歳くらいからこんな感じに。
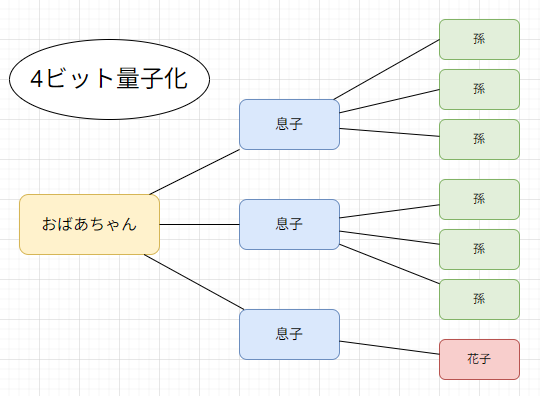
80歳近くになるともうこんな感じだったと思う。
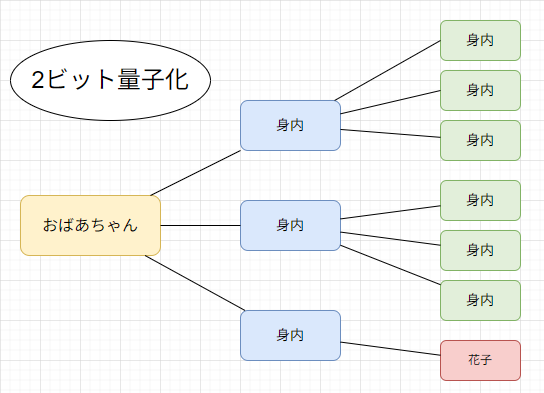
もはや息子も孫も一緒くた。 男の名前は、最後のほうは「最早覚える気ないやろ」ってツッコミ入れたくなるレベルでした。
同性だからか少数だからか、わりと女性の名前は憶えてた気がする。
おばあちゃんがすごいのは、ちゃんと配列で
[”たろう”,”じろう”,”さぶろう”,”たかし”,・・・]って頭の中に持ってて、身内の男と思うと片っ端から読み上げていくんです。こっちのリアクション見ながら。当たるまで(笑)
いつも「ばあちゃん、俺はたかしよ~」ってな具合。でもまあコミュニケーションにはそんなに困らなかったのかも。
名付けて、
メモリ省エネアルゴリズムおばあちゃん。(笑
と、まあそんな感じで。
我が家に限らず高齢の方にはよく見られる現象だと思います。
最後に一つ
ビット量子化は不可逆
なんですよね。小数点以下を捨てるから当たり前なんですが。
だから、記憶することを省エネ化しすぎるとどんどん取返しがつかなくなってくる気がするので気を付けようと思った。という話でもあり、
また、ある意味で 忘れたりボケたりすることって、脳の消費を抑えて生きていくための知恵なのかもね~ と思ったりしたという話でした。
たくさん知識を取り入れて、重みを最適化してうまく量子化して、大事なことは残しながら、軽量に思考できる脳を作っていく。 というのが理想なんでしょうね。
おばあちゃんも、めちゃめちゃボケてたけど最後の最後まで息子の心配してたな。。。
本当に大事なことは忘れない。のでしょうね。
